
Conversation Scoring
Every Call. Fairly Scored.
Voiso’s Conversation Scoring brings objectivity to your call reviews. Track tone, accuracy, and compliance in real time, so you can coach smarter, not harder.
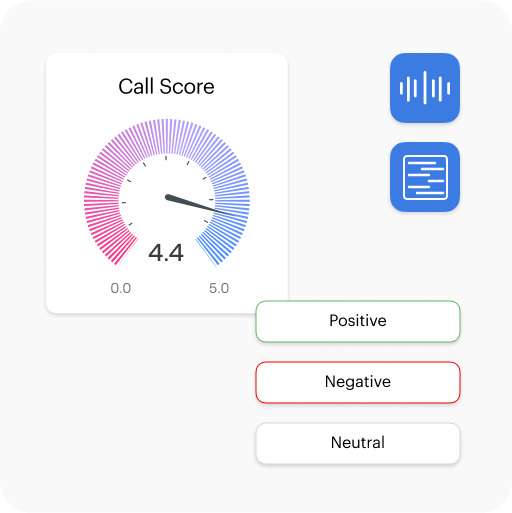
Your Scoring, Your Way
Custom Categories for Every Function
No two teams define a “great call” the same way.
Voiso lets you configure scoring frameworks for support, sales, collections, and more, each with tailored metrics that match their unique goals.
Whether it’s empathy for support or objection handling in sales, you measure what moves the needle.
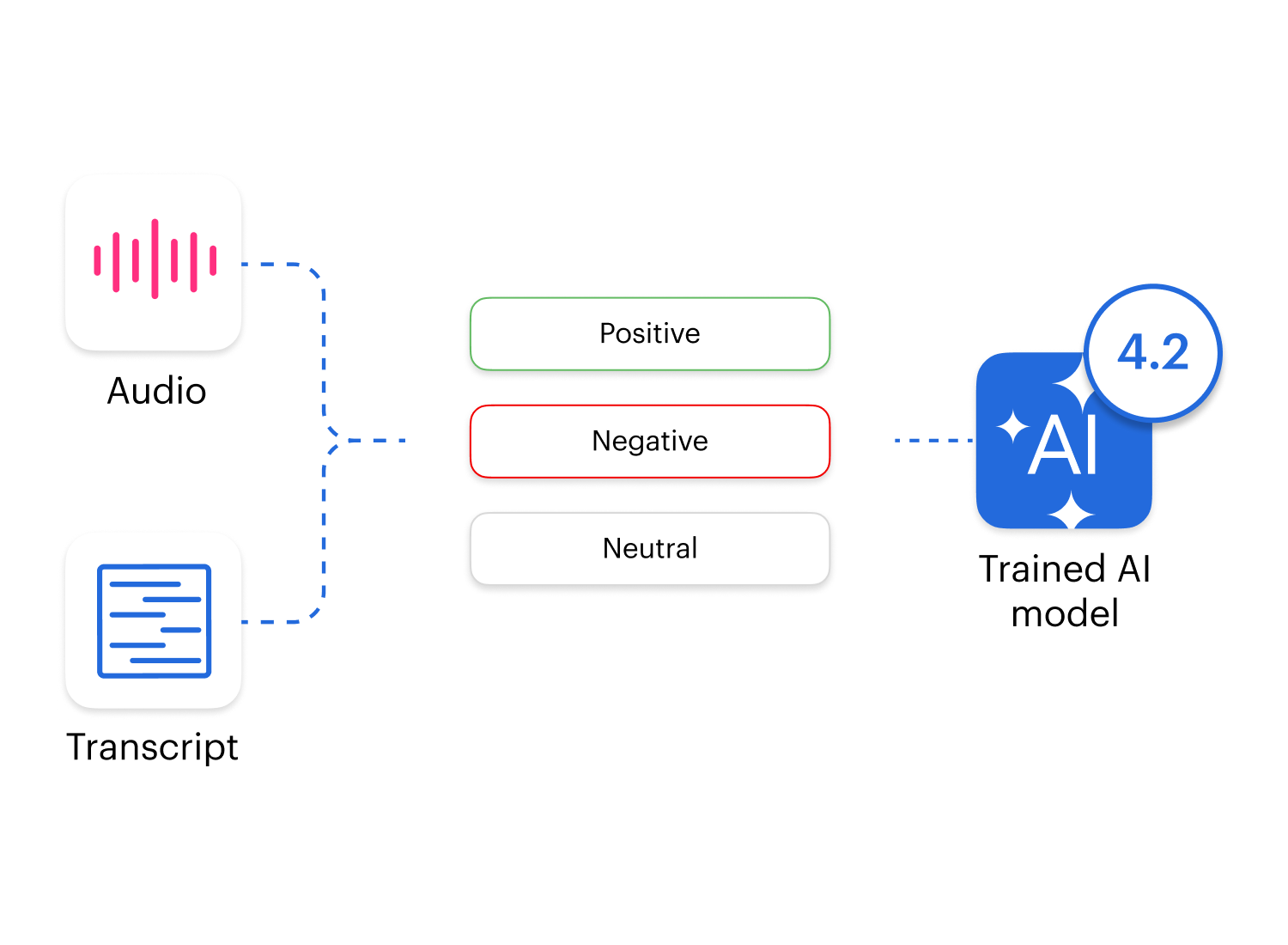
CRM-Triggered Evaluations
Let real-world context drive deeper insights.
Trigger scoring automatically when specific events happen, like a refund request, a missed SLA, or a closed deal.
Every scorecard is enriched with CRM context, so you’re not just grading calls, you’re understanding them.
Multichannel Scoring Made Simple
Voice, chat, or email, every touchpoint counts.
Voiso applies consistent scoring logic across all channels, so your QA team doesn’t need to reinvent the wheel for chat or email reviews.
Unified feedback means faster ramp-ups and tighter training loops.
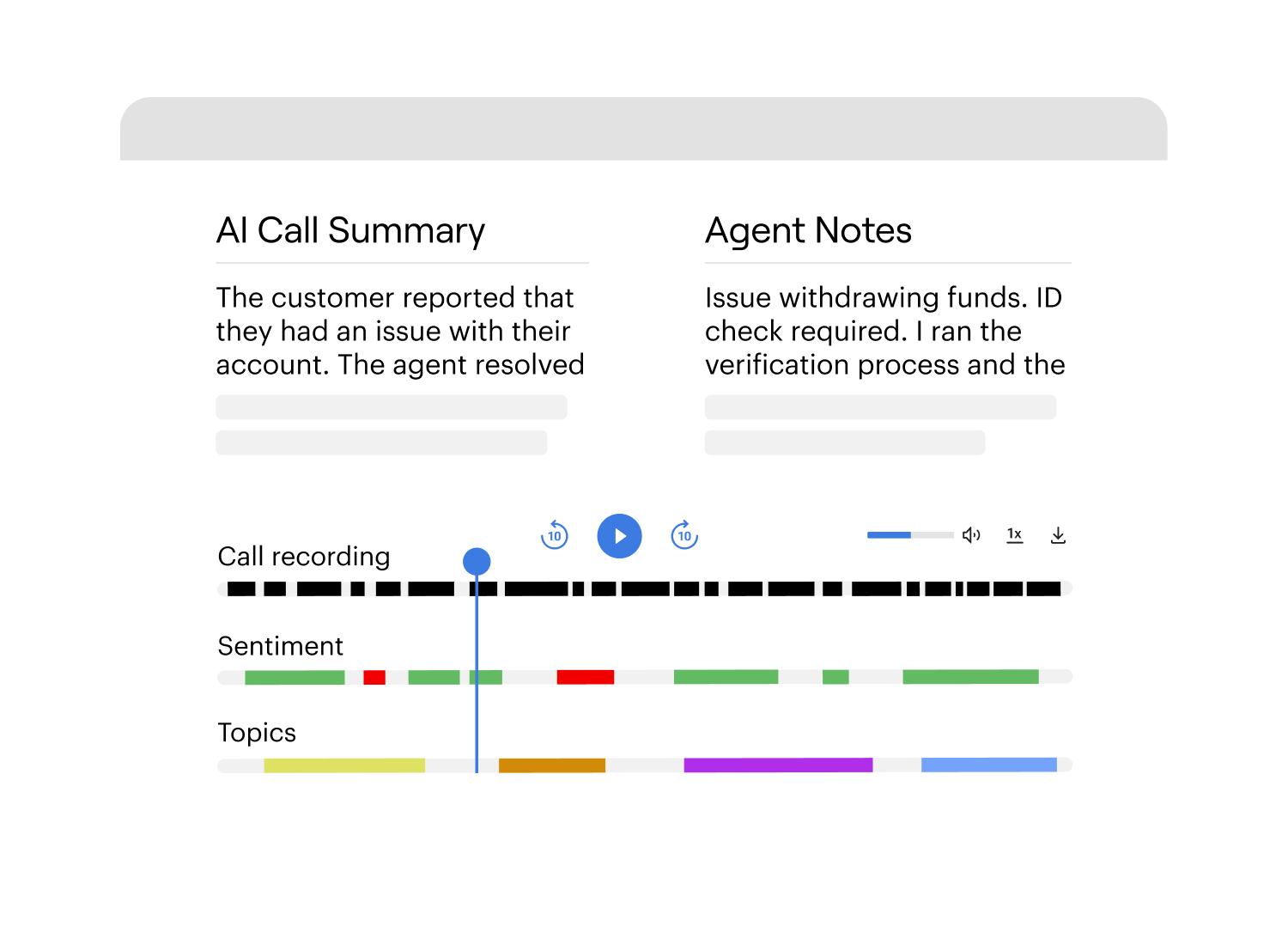
See What’s Working and What Needs Work

customers





Get started in less than 24 hours
FAQ
How does conversation scoring differ from sentiment analysis?
It’s a fair question. On the surface, they might sound interchangeable, both involve analysing dialogue and interpreting meaning. But their core functions and outputs are really quite distinct. Sentiment analysis focuses primarily on emotional tone: was the speaker happy, upset, frustrated? It categorises feelings. That’s useful, especially in brand monitoring or social media listening.
Conversation scoring, on the other hand, digs into structure, compliance, content accuracy, and outcome. It’s not just about how someone felt but whether the conversation met its objective, whether that’s resolving a complaint, closing a deal, or following internal protocol.
Another thing: sentiment analysis is typically one-directional. It might only interpret customer input. Conversation scoring evaluates the full exchange. Agent + customer. Word choice + response time. Tone + factual accuracy. So, while both offer value, scoring paints a more complete picture, like judging a chess game, not just a single move.
Can conversation scoring be biased or inaccurate?
Absolutely, it can be, especially if the scoring system isn’t well-defined or balanced. Here’s where things can get tricky: if your scoring rubric favours scripted conversations, you might end up penalising agents who solve problems creatively. That doesn’t mean they’re doing worse; it just means the system isn’t capturing nuance. And if you’re using AI scoring without enough training data, or worse, biased data, you’ll likely see patterns that favour certain speech styles, accents, or even genders.
Also, let’s be honest, some scoring categories are inherently subjective. “Was the tone friendly?” or “Did the agent sound empathetic?” These can shift based on cultural expectations or even personal preferences of evaluators. That’s why it’s important to blend AI scoring with periodic human review. A hybrid model works best.
To minimise bias, use diverse datasets, revise your rubric frequently, and monitor outliers. If an entire team suddenly sees a score dip without cause, the issue may not be performance, it could be the scoring logic.
How do you introduce conversation scoring to your team without resistance?
If you’ve ever rolled out a new tool that tracks performance, you’ll know, agents can get nervous. And it’s understandable. Nobody wants to feel like they’re being judged by a robot, or worse, punished for things outside their control. So, the first step is transparency.
Explain what’s being scored, how it helps, not just the business, but them as professionals. Position it as a growth tool, not a grading system. Share real examples where low scores uncovered miscommunication and led to simple fixes. Show them how good scores lead to recognition, not just reports.
Another tip: involve team leads in the rollout. If they believe in the tool, they’ll help others trust it too. Let agents try it on mock calls first. Show them how feedback works. Keep the feedback private at first, no public dashboards until there’s comfort.
In short, empathy goes a long way. Make it clear: this isn’t about catching mistakes. It’s about getting better, together.